Google CASA (Campus Activated Subscriber Access) ist ein kostenloser Service, der Nutzer/innen von institutionellen Zeitschriftenlizenzen über die Plattform Google Scholar den Zugang von außerhalb ihres institutionellen Netzwerks ermöglicht (Remote Access), ohne dass dazu eigene technische Maßnahmen getroffen werden müssen (Proxy-Server, Link-Resolver o.ä.).
- Der/die Nutzerin sucht bei Google Scholar innerhalb der IP-Range der Institution nach Fachartikeln – zu den institutionell lizenzierten Artikeln erscheinen bei den Suchergebnissen automatisch Links zu den PDFs analog zu den generell frei verfügbaren Artikeln.
- Ist der/die Nutzer/in mit einem persönlichen Konto bei Google angemeldet und klickt auf einen dieser Links, wird eine Verknüpfung der Lizenz des Anbieters mit diesem Konto bei Google angelegt.
- Meldet sich der/die Nutzer/in anschließend mit dem Konto außerhalb der IP-Range – z.B. zuhause – bei Google an, werden bei einer Google-Scholar-Suche wieder die Links zum Volltext des Anbieters angezeigt. Nach Aufruf eines Links können auch ohne Google Scholar alle lizenzierten Artikel des Anbieters geöffnet werden.
- Um eine Anzeige der Links zu verhindern, kann man bei den Einstellungen in Google Scholar kann man unter „Konto“ bzw. „Account“ ein Häkchen bei „Signed-in off-campus access links“ entfernen.
- Voraussetzung ist eine Teilnahme des Anbieters und der Institution bei Google CASA bzw. dem „Subscriber Links“-Programm.
Die hier dargestellten Informationen stammen von den Verlagen oder aus eigenen Testungen, Google selbst bietet keinerlei Informationen zu diesem Programm an. Die ausführlichsten mir bekannten Informationen, auch über die technischen Hintergründe, finden sich bei Elsevier: https://service.elsevier.com/app/answers/detail/a_id/29795/supporthub/sciencedirect/kw/casa/
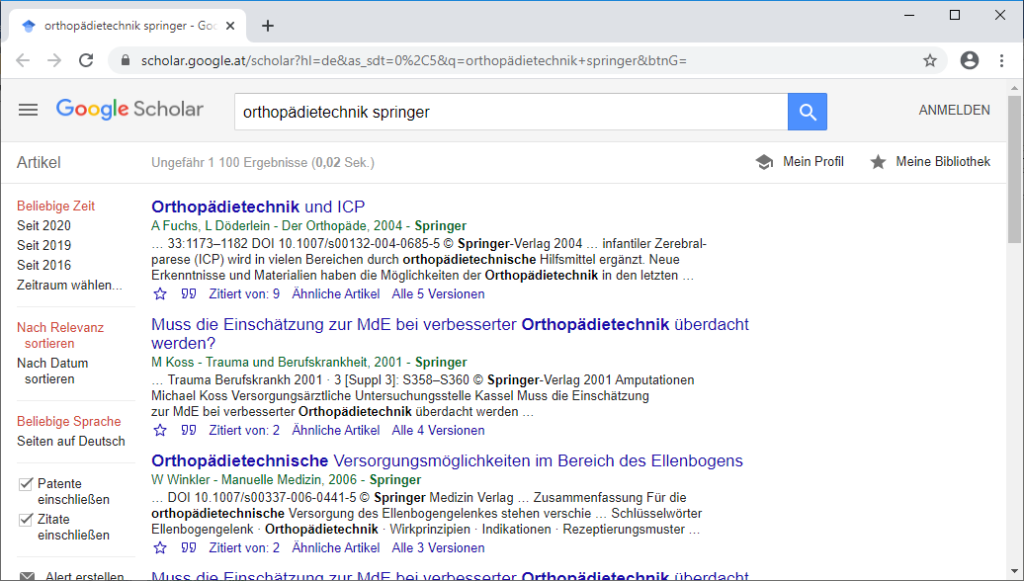
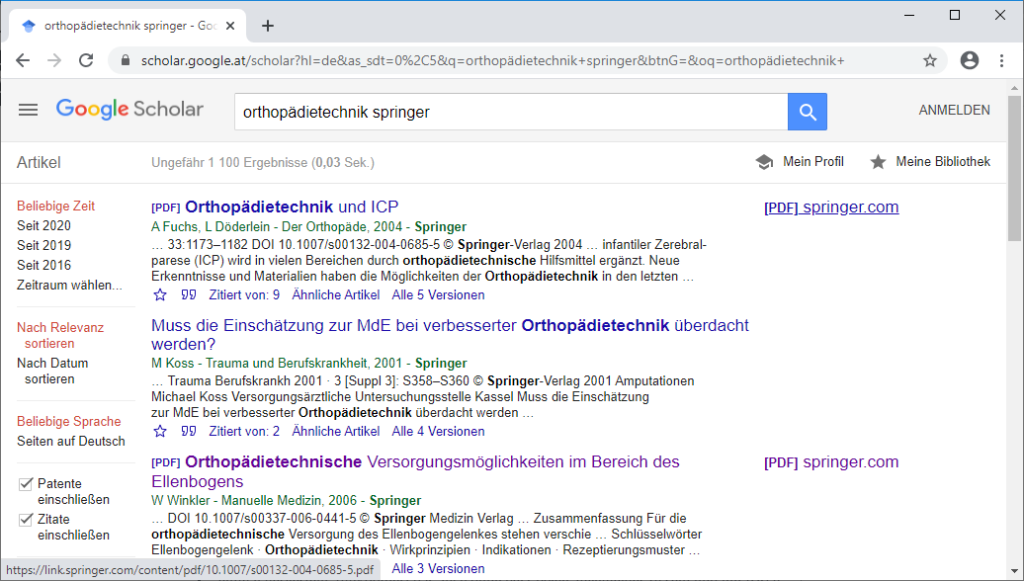
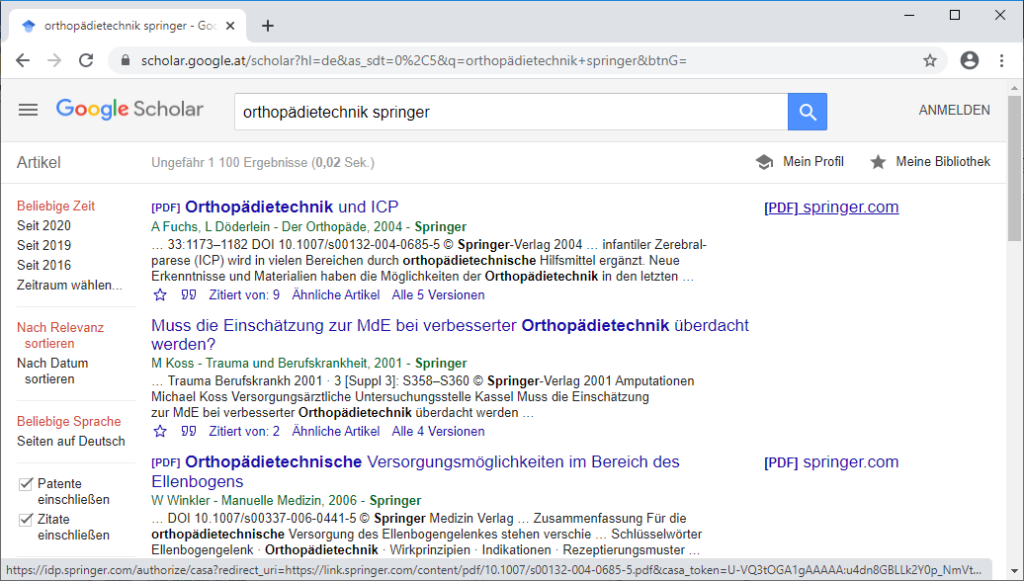
Vieles bleibt unklar:
- Wie kommt man als Institution in das „Subscriber Links“-Programm und wie wieder hinaus? Funktioniert eine Registrierung bei einem Verlag dann auch für die anderen? (Scheint so …) Wird man als institutioneller Kunde automatisch registriert und hat nur ein Opt-out? (Elsevier deutet so etwas an, jedenfalls für „academic customers“). Highwire schreibt, man könne sich als Institution nicht gegen Google Casa entscheiden. (https://www.highwirepress.com/resources/data-sheets/casa-faq/)
- Wie sind die technischen Hintergründe? Was wird wann und wo gespeichert? Welche Rolle spielen Cookies? Wie ist es mit dem Datenschutz? Wenn man etwa einen Artikel bei Elsevier oder Springer über Google CASA auf dem Privatrechner geöffnet hat, erscheinen bei Google Scholar die Links zu den PDFs anschließend auch, wenn alle Browserdaten und Cookies gelöscht wurden und man nicht bei Google Scholar angemeldet ist (s.o.) – vermutlich speichert Google oder der Verlag also auch die private IP-Adresse in diesem Zusammenhang. Hierzu gibt es meines Wissens keine Vereinbarungen, Datenschutzerklärungen etc., im Unterschied zu jeder Webseite bei der Cookies zum Einsatz kommen, gibt es auch keine Browserbenachrichtigungen, dass man jetzt den Google-CASA-Service nutzt.
- Wird der Service von unterschiedlichen Anbietern unterschiedlich angeboten? Warum gibt es kein zentrales Administrationsinterface bei Google? Konkret habe ich selbst vor längerer Zeit schon das damalige Angebot vom NEJM, diese Möglichkeit des Fernzugriffs in unseren Krankenhäusern anzubieten, ganz informell per Mail angenommen und seitens des NEJM auch keine genaueren Informationen erhalten. Seither schien das für alle Anbieter zu funktionieren, ohne dass ich benachrichtigt wurde oder man als Google-Scholar-Nutzer innerhalb unseres Netzwerks irgendwie informiert würde, beim Testen für diesen Artikel ging es jetzt für das NEJM nicht mehr, bei anderen aber schon obwohl ich mit diesen Anbietern zu CASA nie einen Kontakt hatte.
- Wie lange werden Daten gespeichert? Anscheinend muss man seine Verbindung alle 30 Tage erneuern, generell werden die Daten 120 Tage gespeichert. Die Angaben dazu sind aber allgemein unklar bzw. bei manchen Anbietern garnicht vorhanden.
- Welche Verlage bieten diesen Service an bzw. geben Lizenzdaten an Google weiter? (Meine kleine unvollständige Liste: Springer, Elsevier, SAGE, NEJM, JSTOR, Highwire, Ingenta …)
- Warum gibt es keine Informationen von oder Vereinbarungen mit Google? Wie gesagt, bei Google selbst sucht man die Begriffe CASA sowie „Subscriber Links“ vergeblich. Es gibt nur eine knappe Seite zu einem ähnlichen Projekt „Library Links“ für Institutionen mit Link Resolver: https://scholar.google.com/intl/en/scholar/libraries.html Ein solcher wird für CASA allerdings nicht benötigt (jedenfalls funktioniert es bei uns ohne).
- Wird ein Google Scholar Account benötigt? Einige Anbieter behaupten, es wäre möglich Google Casa auch ohne Google Scholar Account zu nutzen, wenn man mit dem gleichen Gerät im und außerhalb des Campus arbeitet. Ich konnte diese Funktionalität nicht nachvollziehen, abgesehen von den bestehenden Remote-Access-Lösungen mit persönlichen Konten bei den Anbietern.
- Wie ist das mit Missbrauchsmöglichkeiten? Ein Google-Account ist schnell erstellt und weitergegeben … aber vielleicht ist das im Vergleich zu Sci-Hub und Co. ohnehin zu umständlich.
Mein vorläufiges Fazit: Ein spannender und toller Service von Google wie so oft, aber erstaunlich unklar und geheimnisvoll in der Umsetzung. Abgesehen davon, dass sich Google Scholar auf diese Weise Dominanz verschafft, sind die weiteren Implikationen für Bibliotheken und auch Verlage m.E. unabsehbar, ebenso wie die Interessen seitens Google ebenfalls komplexer sein dürften. Die Situation, dass nützliche Services mit einer unklaren Menge von möglichen Implikationen verschiedenster Art (rechtlich, wirtschaftlich, auch bibliothekarisch) einhergehen und Entscheidungen auf einer sehr oberflächlichen Wissensbasis getroffen werden müssen, scheint inzwischen Standard zu werden – wenn solche Entscheidungen überhaupt noch getroffen werden können, wie sich in diesem Fall ja schon andeutet.
Ich freue mich über Ihre Meinung und auch über genauere Informationen über die Hintergründe, wenn sie jemand hat …